Etsy features a diverse marketplace of unique handmade and vintage items. It’s a visually diverse marketplace as well, and computer vision has become increasingly important to Etsy as a way of enhancing our users’ shopping experience. We’ve developed applications like visual search and visually similar recommendations that can offer buyers an additional path to find what they’re looking for, powered by machine learning models that encode images as vector representations.
Learning expressive representations through deep neural networks, and being able to leverage them in downstream tasks at scale, is a costly technical challenge. The infrastructure required to train and serve large models is expensive, as is the iterative process that refines them and optimizes their performance. The solution is often to train deep learning architectures offline and use the pre-computed pretrained visual representations in downstream tasks served online. (We wrote about this in a previous blog post on personalization from real-time sequences and diversity of representations.) In any application where a query image representation is inferred online, it’s important that you have low latency, memory-aware models. Efficiency becomes paramount to the success of these models in the product. We can think about efficiency in deep learning along multiple axes: efficiency in model architecture, model training, evaluation and serving.
Model Architecture
The EfficientNet family of models features a convolutional neural network architecture. It uniformly optimizes for network width, depth, and resolution using a fixed set of coefficients. By allowing practitioners to start from a limited resource budget and scale up for better accuracy as more resources are available, EfficientNet provides a great starting point for visual representations. We began our trials with EfficientNetB0, the smallest size model in the EfficientNet family. We saw good performance and low latency with this model, but the industry and research community have touted Vision Transformers (ViT) as having better representations. We decided to give that a try.
Transformers lack the spatial inductive biases of CNN, but they outperform CNN when trained on large enough datasets and may be more robust to domain shifts. ViT decomposes the image into a sequence of patches (16X16 for example) and applies a transformer architecture to incorporate more global information. However, due to the massive number of parameters and compute-heavy attention mechanism, ViT-based architectures can be many times slower to train and inference than lightweight Convolutional Networks. Despite the challenges, more efficient ViT architectures have recently begun to emerge, featuring clever pooling, layer dropping, efficient normalization, and efficient attention or hybrid CNN-transformer designs.
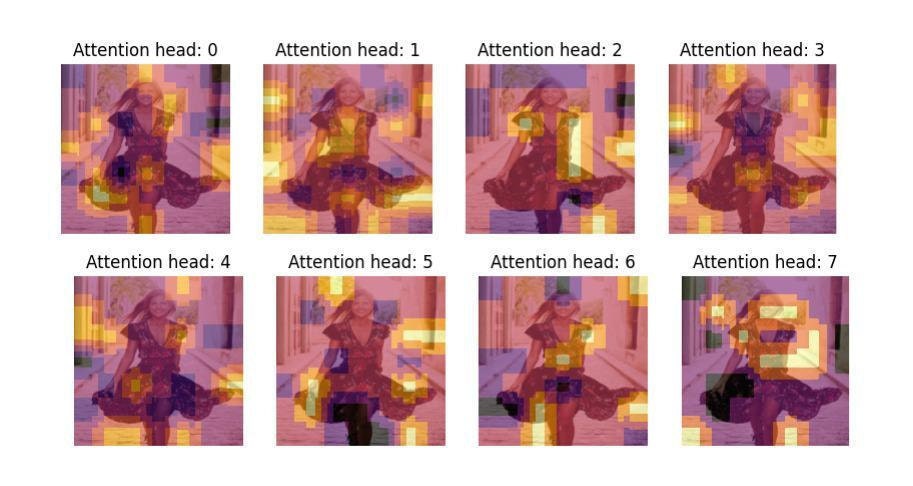
We employ the EfficientFormer-l3 to take advantage of these ViT improvements. The EfficientFormer architecture achieves efficiency through downsampling multiple blocks and employing attention only in the last stage. This derived image representation mechanism differs from the standard vision transformer, where embeddings are extracted from the first token of the output. Instead, we extract the attention from the last block for the eight heads and perform average pooling over the sequence. In Figure 2 we illustrate these different attention weights with heat maps overlaid on an image, showing how each of the eight heads learns to focus on a different salient part.
Model Training
Fine-Tuning
With our pre-trained backbones in place, we can gain further efficiencies via fine tuning. For the EfficientNetB0 CNN, that means replacing the final convolutional layer and attaching a d-dimensional embedding layer followed by m classification heads, where m is the number of tasks. The embedding head consists of a new convolutional layer with the desired final representation dimension, followed by a batch normalization layer, a swish activation and a global average pooling layer to aggregate the convolutional output into a single vector per example. To train EfficientNetB0, new attached layers are trained from scratch for one epoch with the backbone layers frozen, to avoid excessive computation and overfitting. We then unfreeze 75 layers from the top of the backbone and finetune for nine additional epochs, for efficient learning. At inference time we remove the classification head and extract the output of the pooling layer as the final representation.
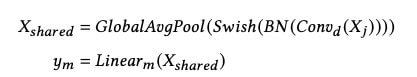
To fine-tune the EfficientFormer ViT we stick with the pretraining resolution of 224X224, since using sequences longer than the recommended 384X384 in ViT leads to larger training budgets. To extract the embedding we average pool the last hidden state. Then classification heads are added as with the CNN, with batch normalization being swapped for layer normalization.
Multitask Learning
In a previous blog post we described how we built a multitask learning framework to generate visual representations for Etsy’s search-by-image experience. The training architecture is shown in Figure 3.
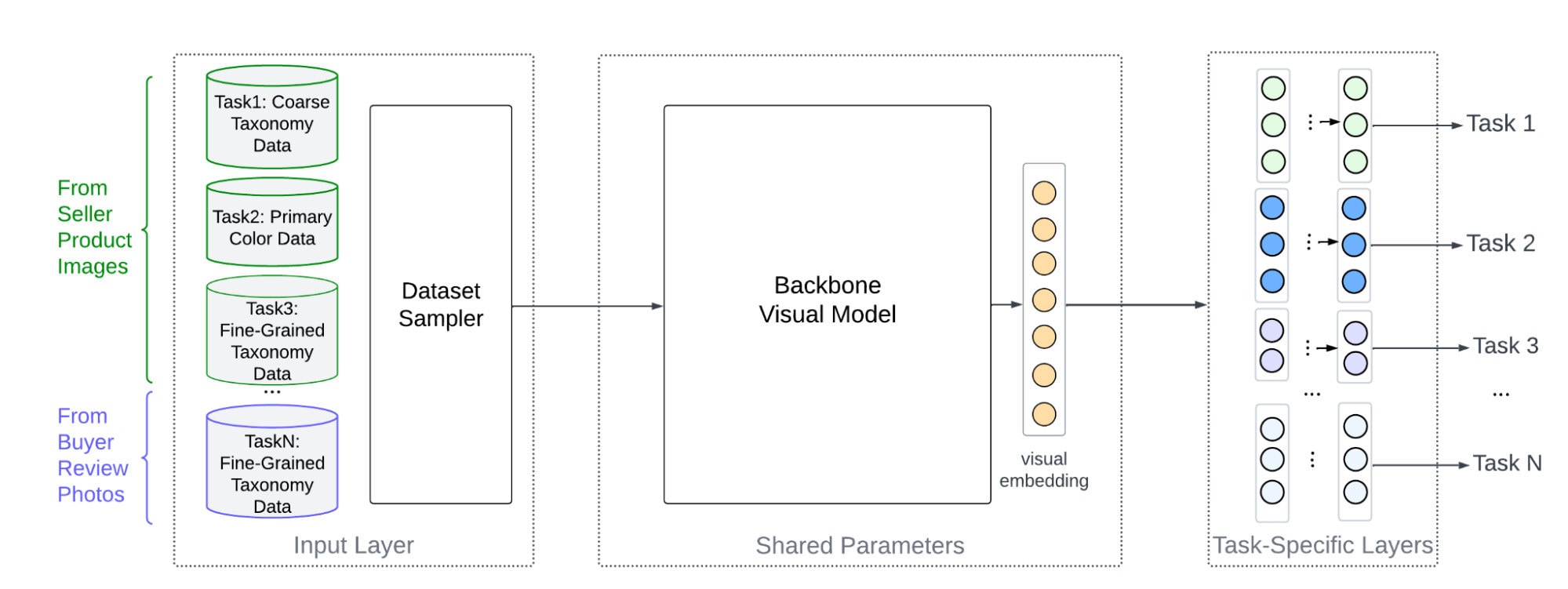
Multitask learning is an efficiency inducer. Representations encode commonalities, and they perform well in diverse downstream tasks when those are learned using common attributes as multiple supervision signals. A representation learned in single-task classification to the item’s taxonomy, for example, will be unable to capture visual attributes: colors, shapes, materials. We employ four classification tasks: a top-level taxonomy task with 15 top-level categories of the Etsy taxonomy tree as labels; a fine-grained taxonomy task, with 1000 fine-grained leaf node item categories as labels; a primary color task; and a fine-grained taxonomy task (review photos), where each example is a buyer-uploaded review photo of a purchased item with 100 labels sampled from fine-grained leaf node item categories.
We are able to train both EfficientNetB0 and EfficientFormer-l3 on standard 16GB GPUs (we used two P100 GPUs). For comparison, a full sized ViT requires a larger 40GB RAM GPU such as an A100, which can increase training costs significantly. We provide detailed hyperparameter information for fine-tuning either backbone in our article.
Evaluating Visual Representations
We define and implement an evaluation scheme for visual representations to track and guide model training, on three nearest neighbor retrieval tasks. After each training epoch, a callback is invoked to compute and log the recall for each retrieval task. Each retrieval dataset is split into two smaller datasets: “queries” and “candidates.” The candidates dataset is used to construct a brute-force nearest neighbor index, and the queries dataset is used to look up the index. The index is constructed on the fly after each epoch to accommodate for embeddings changing between training epochs. Each lookup yields K nearest neighbors. We compute Recall@5 and @10 using both historical implicit user interactions (such as “visually-similar ad clicks”) and ground truth datasets of product photos taken from the same listing (“intra-item”). The recall callbacks can also be used for early stopping of training to enhance efficiency.
The intra-item retrieval evaluation dataset consists of groups of seller-uploaded images of the same item. The query and candidate examples are randomly selected seller-uploaded images of an item. A candidate image is considered a positive example if it is associated with the same item as the query. In the “intra-item with reviews” dataset, the query image is a randomly selected buyer-uploaded review image of an item, with seller-uploaded images providing candidate examples. The dataset of visually similar ad clicks associates seller-uploaded primary images with primary images of items that have been clicked in the visually similar surface on mobile. Here, a candidate image is considered a positive example for some query image if a user viewing the query image has clicked it. Each evaluation dataset contains 15,000 records for building the index and 5,000 query images for the retrieval phase.
We also leverage generative AI for an experimental new evaluation scheme. From ample, multilingual historical text query logs, we build a new retrieval dataset that bridges the semantic gap between text-based queries and clicked image candidates. Text-to-image generative stable diffusion makes the information retrieval process language-agnostic, since an image is worth a thousand (multilingual) words. A stable diffusion model generates high-quality images which become image queries. The candidates are images from clicked items corresponding to the source text query in the logs. One caveat is that the dataset is biased toward the search-by-text production system that produced the logs; only a search-by-image-from-text system would produce truly relevant evaluation logs. The source-candidate image pairs form the new retrieval evaluation dataset which is then used within a retrieval callback.
Of course, users entering the same text query may have very different ideas in mind of, say, the garment they’re looking for. So for each query we generate several images: formally, a random sample of length 𝑛 from the posterior distribution over all possible images that can be generated from the seed text query. We pre-condition our generation on a uniform “fashion style.” In a real-world scenario, both the text-to-image query generation and the image query inference for retrieval happen in real time, which means efficient backbones are necessary. We randomly select one of the 𝑛 generated images to replace the text query with an image query in the evaluation dataset. This is a hybrid evaluation method: the error inherent in the text-to-image diffusion model generation is encapsulated in the visually similar recommendation error rate. Future work may include prompt engineering to improve the text query prompt itself, which as input by the user can be short and lacking in detail.
Large memory requirements and high inference latency are challenges in using text-to-image generative models at scale. We employ an open source fast stable diffusion model through token merging and float 16 inference. Compared to the standard stable diffusion implementation available at the time we built the system, this method speeds up inference by 50% with a 5x reduction in memory consumption, though results depend on the underlying patched model. We can generate 500 images per hour with one T4 GPU (no parallelism) using the patched stable diffusion pipeline. With parallelism we can achieve further speedup. Figure 4 shows that for the English text query “black bohemian maxi dress with orange floral pattern” the efficient stable diffusion pipeline generates five image query candidates. The generated images include pleasant variations with some detail loss. Interestingly, mostly the facial details of the fashion model are affected, while the garment pattern remains clear. In some cases degradation might prohibit display, but efficient generative technology is being perfected at a fast pace, and prompt engineering helps the generative process as well.

Efficient Inference and Downstream Tasks
Especially when it comes to latency-sensitive applications like visually similar recommendations and search, efficient inference is paramount: otherwise, we risk loss of impressions and a poor user experience. We can think of inference along two axes: online inference of the image query and efficient retrieval of top-k most similar items via approximate nearest neighbors. The dimension of the learned visual representation impacts the efficient retrieval design as well, and the smaller 256d derived from the EfficientNetB0 presents an advantage. EfficientNet B0 is hard to beat in terms of accuracy-to-latency trade-offs for online inference, with ~5M parameters and around 1.7ms latency on iPhone 12. The EfficientFormer-l3 has ~30M parameters and gets around 2.7ms latency on iPhone 12 with higher accuracy (while for example MobileViT-XS scores around 7ms with a third of accuracy; very large ViT are not considered since latencies are prohibitive). In offline evaluation, the EfficientFormer-l3-derived embedding achieves around +5% lift in the Intra-L Recall@5 evaluation, a +17% in Intra-R Recall@5, and a +1.8% in Visually Similar Ad clicks Recall@5.
We performed A/B testing on the EfficientNetB0 multitask variant across visual applications at Etsy with good results. Additionally, the EfficientFormer-l3 visual representations led to a +0.65% lift in CTR, and a similar lift in purchase rate in a first visually-similar-ads experiment when compared to the production variant of EfficientNetB0. When included in sponsored search downstream rankers, the visual representations led to a +1.26% lift in post-click purchase rate. Including the efficient visual representation in Ads Information Retrieval (AIR), an embedding-based retrieval method used to retrieve similar item ad recommendations caused an increase in click-recall@100 of 8%. And when we used these representations to compute image similarity and included them directly in the last-pass ranking function, we saw a +6.25% lift in clicks.
The first use of EfficientNetB0 visual embeddings was in visually similar ad recommendations on mobile. This led to a +1.92% increase in ad return-on-spend on iOS and a +1.18% increase in post-click purchase rate on Android. The same efficient embedding model backed the first search-by-image shopping experience at Etsy. Users search using photos taken with their mobile phone’s camera and the query image embedding is inferred efficiently online, which we discussed in a previous blog post.
Learning visual representations is of paramount importance in visually rich e-commerce and online fashion recommendations. Learning them efficiently is a challenging goal made possible by advances in the field of efficient deep learning in computer vision. If you’d like a more in-depth discussion of this work, please see our full accepted paper to the #fashionXrecsys workshop at the Recsys 2023 conference.
Post a Comment